Actionable Intelligence. Accelerated.
Break down the silos of inefficiency and get to the big picture faster than ever before with Truxton.
Truxton is a complementary platform to your forensic tools that automates forensic analysis, unifies the discovery and correlation of artifacts/evidence, and delivers actionable information to investigators in any operational environment.
Truxton is a force multiplier that will save your organization time, manpower, and money. It will also improve cooperation, communication and coordination with remote offices and partner organizations. Best of all, it’s proudly Made in the USA.

Why Truxton?
Aggregate All Your Digital Media

Investigate all your forensic images together in a single workspace, so you can solve cases with disparate data sources easier than ever. Truxton conquers the challenges of volume, variety, and big data to help you increase the speed, efficiency, and success of every investigation.
Automate Exploitation, Alerts, and Reporting
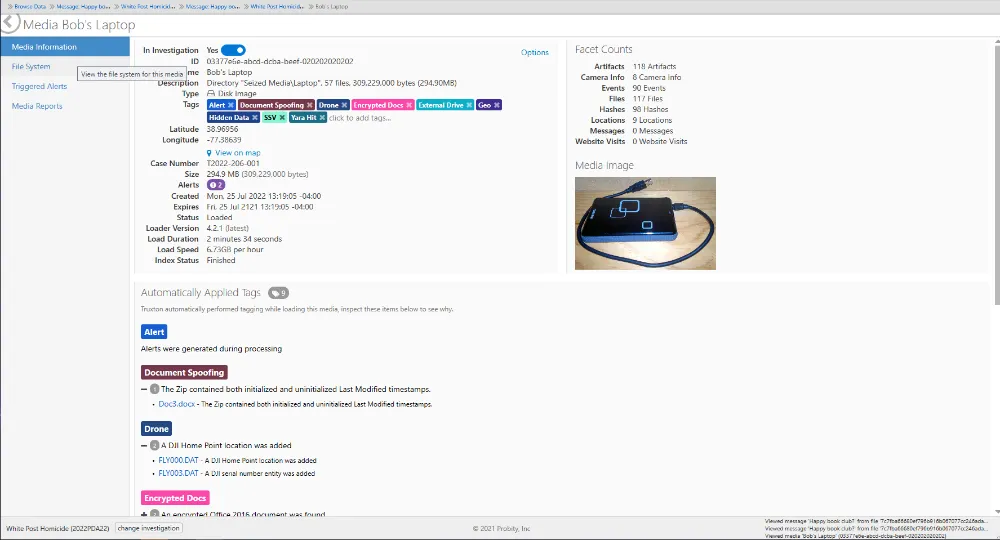
Say goodbye to searching file piles of data and manually creating reports from multiple tools. Truxton automatically discovers and tags important artifacts and entities and provides instant summary reports that help you get to actionable information faster than ever before.
Correlate Artifacts from Disparate Media
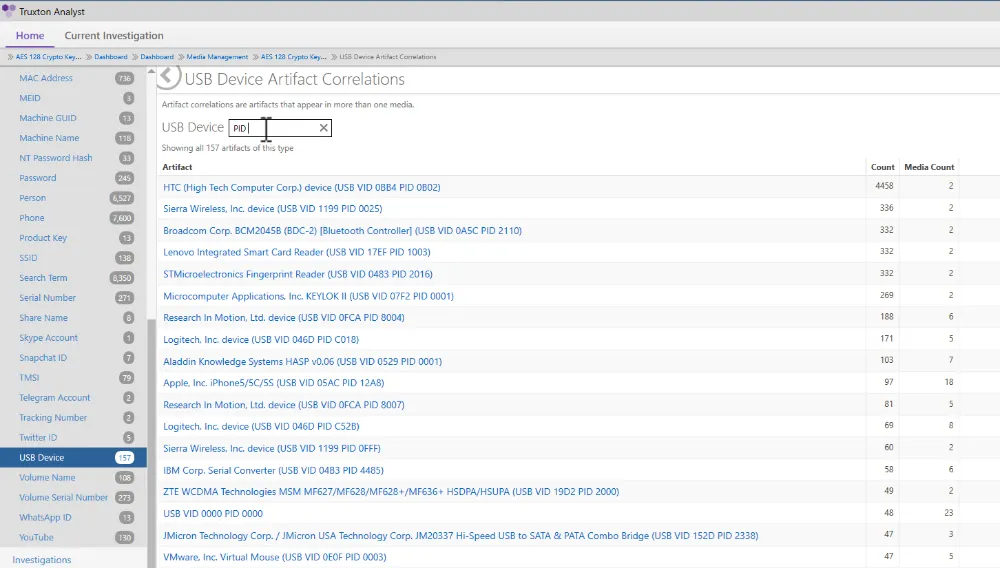
Stop wasting time manually compiling the results from multiple tools. Truxton automatically takes the names, locations, phone numbers, and events from all the media in your case and creates simple, easy-to-understand visualizations and reports.
Collaborate on Investigations Simultaneously
Truxton's Multi-User & Enterprise Versions allow multiple investigators to simultaneously work on the same investigation and share notes, findings, and reports in real time- even if you're at multiple locations! Truxton's unique Coordinated Rapid Review feature allows teams to analyze and mark unlimited images and videos in a gallery format for fast, efficient identification of important files.
Truxton Delivers
Automated Reports
Truxton lets investigators cut through the chaff and get to the data that matters fast. Our automated reports provide instant, downloadable summaries of the information you need to paint a complete picture of every case- right from the start. There’s even a KMZ download report for quick, easy review in Google Earth, Bing, or your favorite Map Server!
Unique Artifacts
Truxton discovers and tags important file entities, so you don’t have to manually search through piles of data for the 20% that matters.
Internal and External Shared Artifacts
Truxton automatically shows you what artifacts appear in multiple phones and other media so you can connect the dots quickly and easily.
Consolidated Contacts
Truxton compiles the address books from all of your media to compile a complete list of names, shared accounts, AKAs and phone/account numbers automatically.
Get text & email alerts when media is done processing and review the results right from your phone
Powerful Visualizations and Location Filtering
The Most Powerful Forensic Timeline
See a complete, visual summary of events across all of your collected evidence that can be downloaded and printed on standard 8.5 x 11” paper.

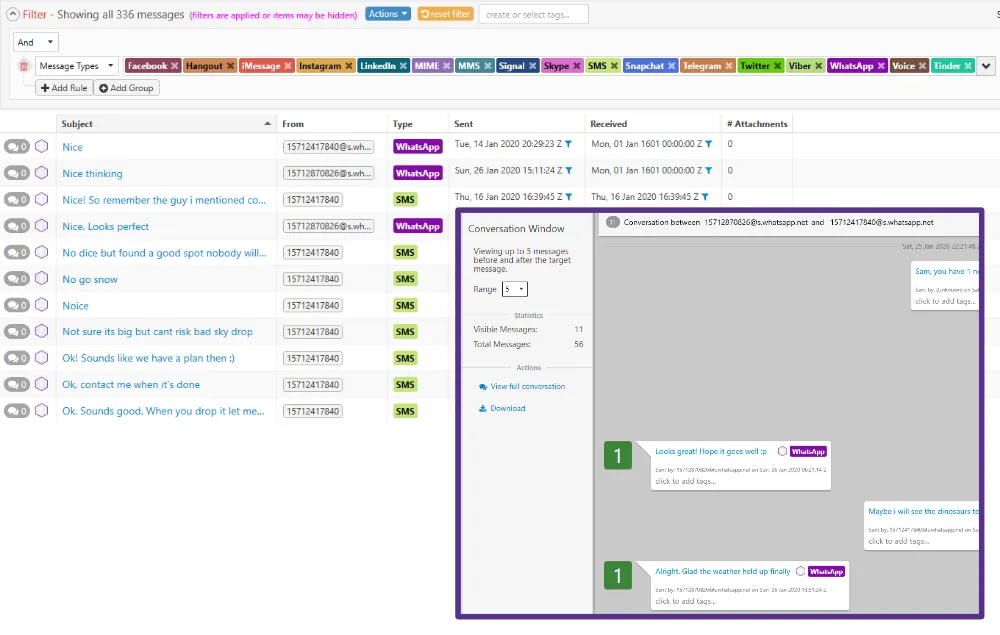
Unified Messaging & Conversation Window
Text, e-mail, and social media messages are unified to present a clear picture of ‘real-time’ conversations. Use the keyword search and messaging window to get right to the heart of any conversation.
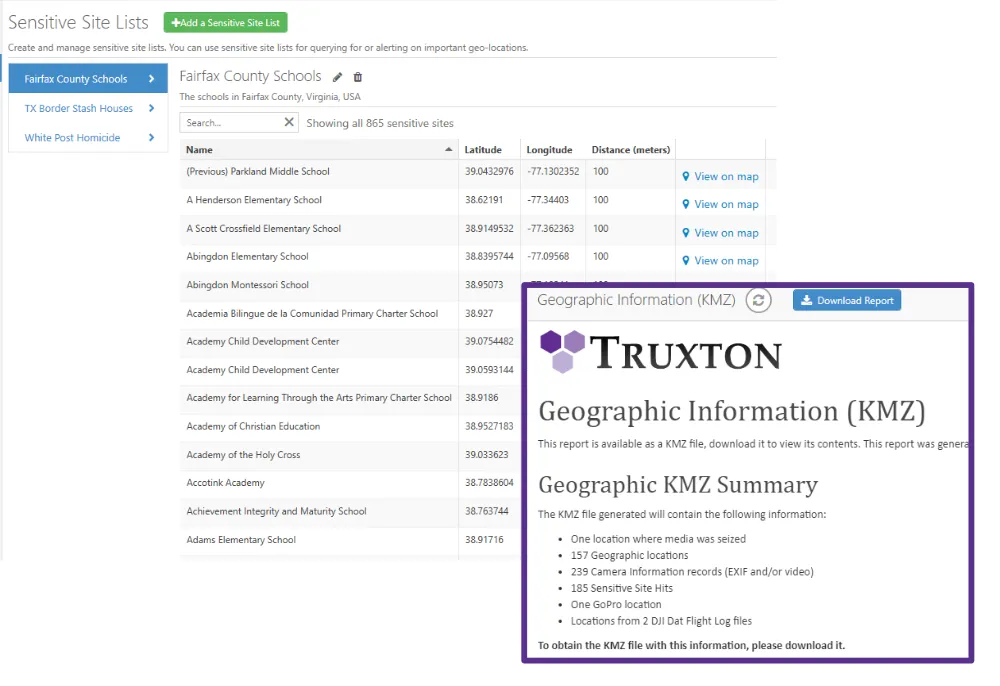
Location, Location, Location
Filter artifacts and evidence by proximity to get an instant picture of event locations like drone home points, wi-fi access, social media activity, automotive data, and movie/photo location. You can even set up geofences to trigger SSV alerts on incoming media.
Play Well with Others
Truxton is designed to load data from your favorite forensic acquisition tools. We’ve also partnered with some of the leading forensic developers, like ADF Solutions, Grayshift, DataPilot, and Detego to create a seamless workflow of data into the Truxton platform.
Have your own special set of forensic tools? Truxton allows you to easily add custom exploitation tools to our automated ETL using non-proprietary programming languages like Python, C++, and C#.
Truxton also integrates with popular OSINT, Mapping, and Big Data Analysis Platforms to let you achieve full forensic fusion.

A Force Multiplier for Forensic Exploitation

Truxton is an affordable complement to all your media acquisition tools that adds automation, efficiency and success to any forensic mission, from the tactical edge to a national lab. It’s a force multiplier that will save your organization time, manpower, and money. It will also improve cooperation, communication and coordination with remote offices and partner organizations. Best of all, it’s proudly Made in the USA.
On-premises, Cloud, and Tactical Edge Capability
Truxton is an enterprise-ready solution that can provide powerful capabilities in any forensic environment.
Laptop / Tablet

Quickly aggregate, triage, and deliver reports right from the field
Forensic Tower / Network

Collaborate on cases, coordinate review of artifacts, findings, images and videos in a team environment
Cloud

Stand up on-demand forensic capability anywhere in the world using AWS or Azure
Truxton Forensic Rack

Process, manage, and store petabytes of data with hundreds or thousands of clients with scalable processing and storage
Ready To Get Started?
Contact us to schedule a demo to see how Truxton can automate, simplify, and save you time on all of your cases.
Need more technical info on the magic of Truxton? Check the Truxton Wiki!
Copyright 2025 Probity, Inc. | Privacy Privacy